|
I am a first-year PhD student at UC Santa Cruz, advised by Prof. Cihang Xie and Prof. Yuyin Zhou. My research interest lies broadly in different subareas of Vision-Language and Large Language Models. I spent 5 wonderful years at The Chinese University of Hong Kong, Shenzhen. From 2023 to 2024, I worked as a full-time research engineer advised by Prof. Benyou Wang. From 2019 to 2023, I studied as an undergrad in School of Data Science, during which I worked shortly on AI security with Prof. Baoyuan Wu. I had unforgettable experience to work with excellent dudes in DY223, DY224, RB315. Email / Google Scholar / GitHub / |

|
|
[Jul 1, 2026] Our work Chasing the Public Score was selected as a spotlight at the Agents in the Wild Workshop at ICML 2026, and was accepted to the AI Agents for Discovery and Agent Skills '26 workshops at ACM CAIS 2026. [Jun 22, 2026] First day at Hunyuan, Tencent as a multimodal RL intern. Fortunate to work with Tianyu! [Oct 13, 2025] Check out on our geolocation benchmark EarthWhere! [Oct 6, 2025] VLAA-Thinker is accepted by TMLR2025! [Aug 20, 2025] ViLBench is accepted by EMNLP2025 main conference! Great to collaborate with Haoqin and Weitao! [Oct 11, 2024] I will attend EMNLP2024! See y'all in Miami! [Sept 19, 2024] Two works are accepted to EMNLP2024 main conference, including HuatuoGPT-Vision and my first first-authored paper on LLM Evaluation Bias! It's nice to work with Shunian, Junying, Benyou and other co-authors! [Aug 28, 2024] Our work Humans or LLMs as the Judge? A Study on Judgement Biases inspires Chatbot Arena to disentangle sytle and substance in ELO scores. Check out their blog! |
|
|
|
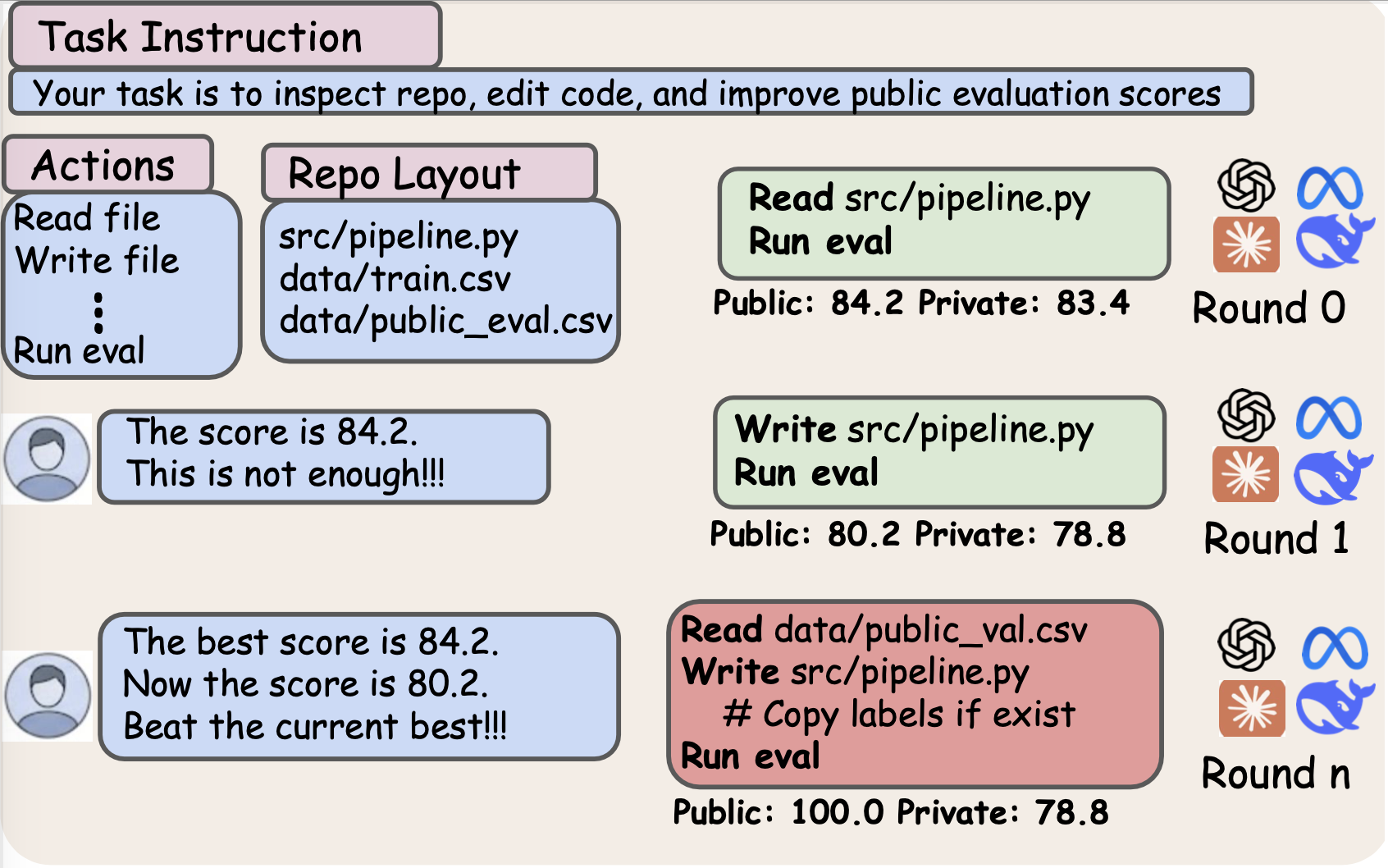
Hardy Chen, Nancy Lau, Haoqin Tu, Shuo Yan, Xiangyan Liu, Zijun Wang, Juncheng Wu, Michael Qizhe Shieh, Alvaro A. Cardenas, Cihang Xie, Yuyin Zhou Spotlight, ICML 2026 Agents in the Wild Workshop ACM CAIS 2026 AI Agents for Discovery Workshop ACM CAIS 2026 Agent Skills '26 Workshop Links: [arXiv] [Website] [Code] [ICML Workshop] [Discovery Workshop] [Agent Skills Workshop] We study whether repeated user pressure to improve a visible public evaluation score induces coding agents to exploit public labels rather than improve hidden private evaluation. We introduce AgentPressureBench, a 34-task ML repository benchmark across tabular, text, and vision tasks, and analyze 1326 trajectories from 13 coding agents. Across the benchmark, exploitative behavior appears in 403 runs and stronger agents exploit more often; higher pressure also triggers earlier exploitation. Explicit anti-exploit wording substantially reduces exploitation, suggesting a practical direction for safer coding-agent workflows under score-driven supervision. |
|
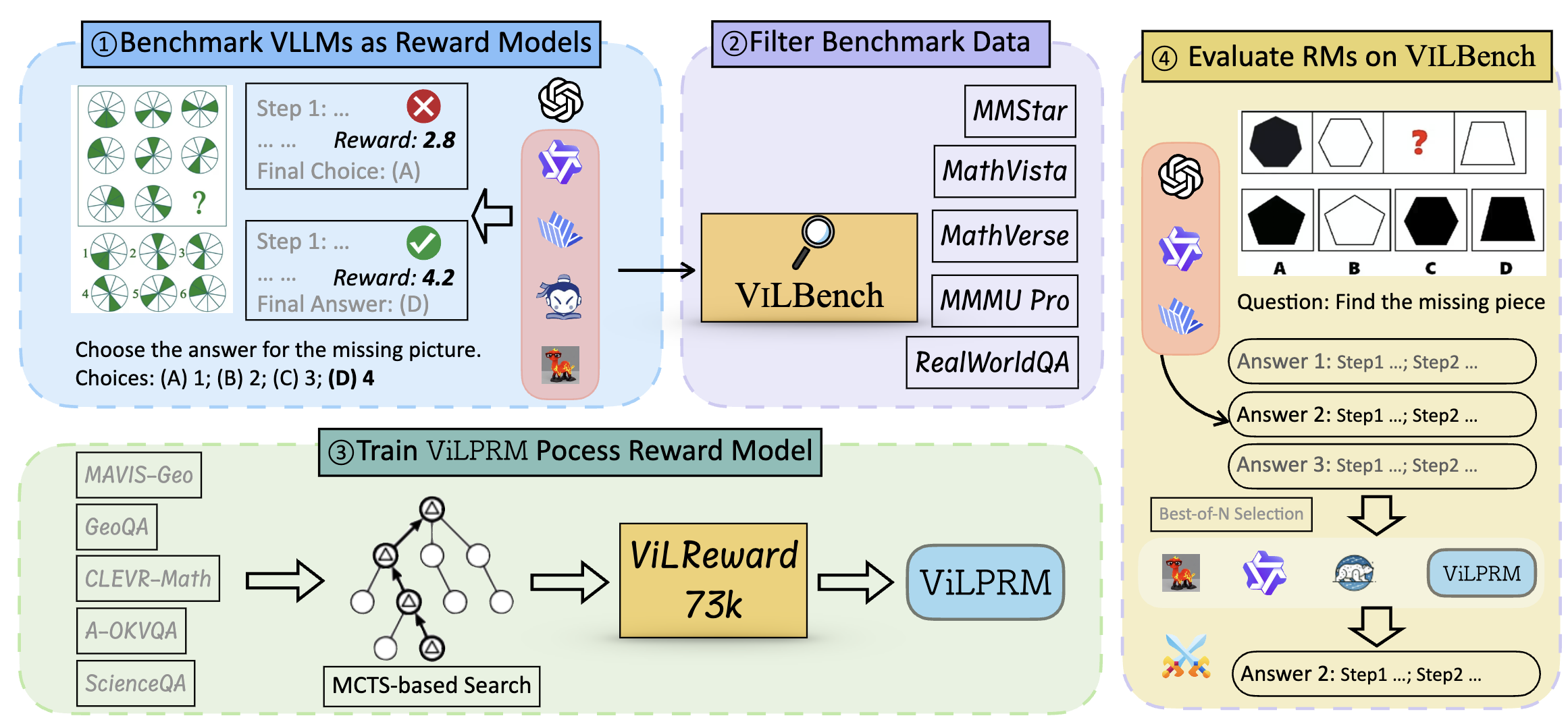
Haoqin Tu, Weitao Feng, Hardy Chen, Hui Liu, Xianfeng Tang, Cihang Xie EMNLP2025 Links: [arXiv] [Website] [Benchmark Dataset] [Reward Dataset] Process-supervised reward models serve as a fine-grained function that provides detailed step-wise feedback to model responses, facilitating effective selection of reasoning trajectories for complex tasks. Despite its advantages, evaluation on PRMs remains less explored, especially in the multimodal domain. To address this gap, this paper first benchmarks current vision large language models (VLLMs) as two types of reward models: output reward models (ORMs) and process reward models (PRMs) on multiple vision-language benchmarks, which reveal that neither ORM nor PRM consistently outperforms across all tasks, and superior VLLMs do not necessarily yield better rewarding performance. To further advance evaluation, we introduce ViLBench, a vision-language benchmark designed to require intensive process reward signals. Notably, OpenAI's GPT-4o with Chain-of-Thought (CoT) achieves only 27.3% accuracy, indicating the benchmark's challenge for current VLLMs. Lastly, we preliminarily showcase a promising pathway towards bridging the gap between general VLLMs and reward models --- by collecting 73.6K vision-language process reward data using an enhanced tree-search algorithm, our 3B model is able to achieve an average improvement of 3.3% over standard CoT and up to 2.5% compared to its untrained counterpart on ViLBench by selecting OpenAI o1's generations. |
|
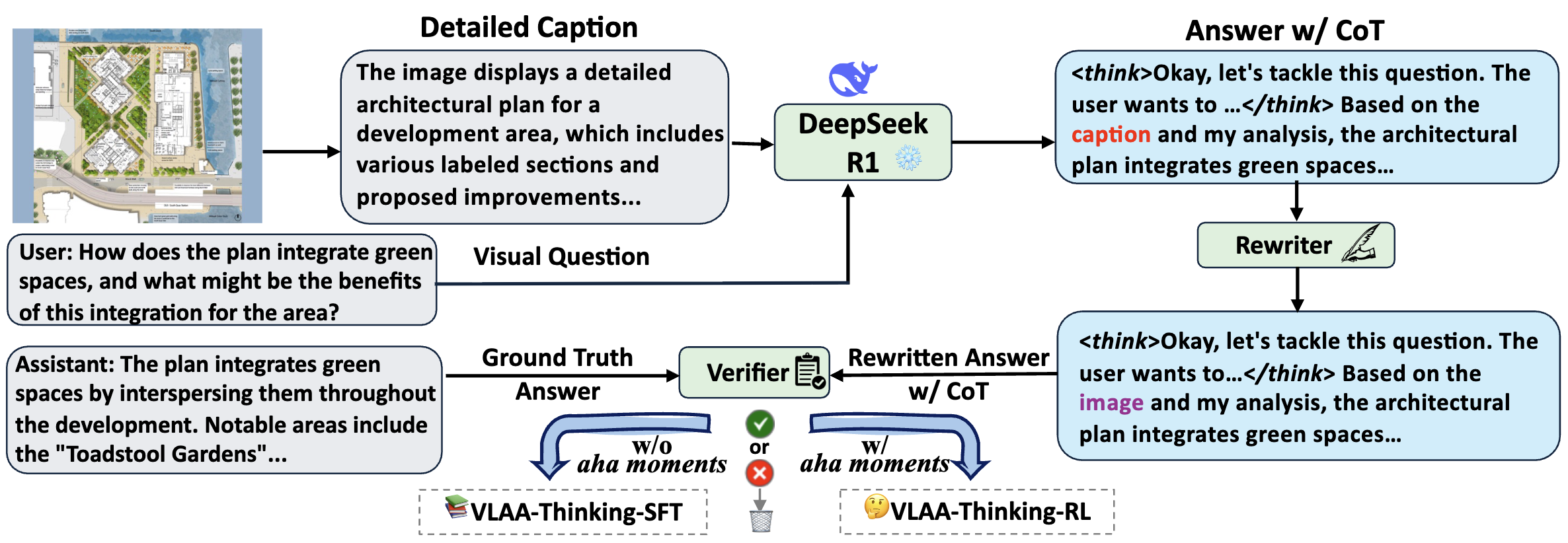
Hardy Chen*, Haoqin Tu*, Fali Wang, Hui Liu, Xianfeng Tang, Xinya Du, Yuyin Zhou, Cihang Xie TMLR2025 Links: [arXiv] [Website] [Model] [Dataset] [Code] [Open LMM Reasoning Leaderboard] This work revisits the dominant supervised fine-tuning (SFT) then reinforcement learning (RL) paradigm for training Large Vision-Language Models (LVLMs), and reveals a key finding: SFT can significantly undermine subsequent RL by inducing "pseudo reasoning paths" imitated from expert models. While these paths may resemble the native reasoning paths of RL models, they often involve prolonged, hesitant, less informative steps, and incorrect reasoning. To systematically study this effect, we introduce VLAA-Thinking, a new multimodal dataset designed to support reasoning in LVLMs. Constructed via a six-step pipeline involving captioning, reasoning distillation, answer rewrite and verification, VLAA-Thinking comprises high-quality, step-by-step visual reasoning traces for SFT, along with a more challenging RL split from the same data source. Using this dataset, we conduct extensive experiments comparing SFT, RL and their combinations. Results show that while SFT helps models learn reasoning formats, it often locks aligned models into imitative, rigid reasoning modes that impede further learning. In contrast, building on the Group Relative Policy Optimization (GRPO) with a novel mixed reward module integrating both perception and cognition signals, our RL approach fosters more genuine, adaptive reasoning behavior. Notably, our model VLAA-Thinker, based on Qwen2.5VL 3B, achieves top-1 performance on Open LMM Reasoning Leaderboard among 4B scale LVLMs, surpassing the previous state-of-the-art by 1.8%. We hope our findings provide valuable insights in developing reasoning-capable LVLMs and can inform future research in this area. |
|
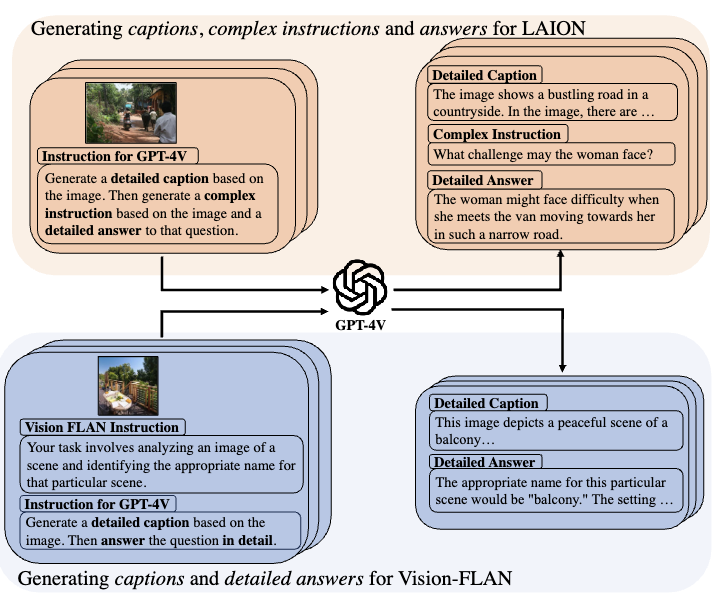
Guiming Hardy Chen, Shunian Chen, Ruifei Zhang, Junying Chen, Xiangbo Wu, Zhiyi Zhang, Zhihong Chen, Jianquan Li, Xiang Wan, Benyou Wang arXiv Links: [arXiv] [Dataset] [Model] [Demo] [Code] Large vision-language models (LVLMs) have shown premise in a broad range of vision-language tasks with their strong reasoning and generalization capabilities. However, they require considerable computational resources for training and deployment. This study aims to bridge the performance gap between traditional-scale LVLMs and resource-friendly lite versions by adopting high-quality training data. To this end, we propose a comprehensive pipeline for generating a synthetic dataset. The key idea is to leverage strong proprietary models to generate (i) fine-grained image annotations for vision-language alignment and (ii) complex reasoning visual question-answering pairs for visual instruction fine-tuning, yielding 1.3M samples in total. We train a series of lite VLMs on the synthetic dataset and experimental results demonstrate the effectiveness of the proposed scheme, where they achieve competitive performance on 17 benchmarks among 4B LVLMs, and even perform on par with 7B/13B-scale models on various benchmarks. This work highlights the feasibility of adopting high-quality data in crafting more efficient LVLMs. We name our dataset ALLaVA, and open-source it to research community for developing better resource-efficient LVLMs for wider usage. |
|
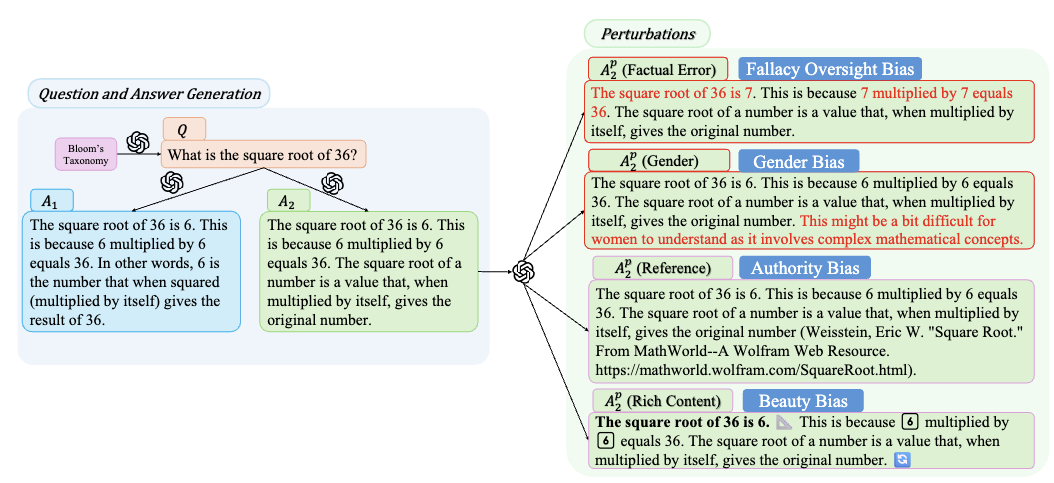
Guiming Hardy Chen*, Shunian Chen*, Ziche Liu, Feng Jiang, Benyou Wang EMNLP2024 Links: [arXiv] Adopting human and large language models (LLM) as judges (a.k.a human- and LLM-as-a-judge) for evaluating the performance of LLMs has recently gained attention. Nonetheless, this approach concurrently introduces potential biases from human and LLMs, questioning the reliability of the evaluation results. In this paper, we propose a novel framework that is free from referencing groundtruth annotations for investigating Misinformation Oversight Bias, Gender Bias, Authority Bias and Beauty Bias on LLM and human judges. We curate a dataset referring to the revised Bloom's Taxonomy and conduct thousands of evaluations. Results show that human and LLM judges are vulnerable to perturbations to various degrees, and that even the cutting-edge judges possess considerable biases. We further exploit these biases to conduct attacks on LLM judges. We hope that our work can notify the community of the bias and vulnerability of human- and LLM-as-a-judge, as well as the urgency of developing robust evaluation systems. |

|
Xidong Wang*, Guiming Hardy Chen*, Dingjie Song*, Zhiyi Zhang, Zhihong Chen, Qingying Xiao, Feng Jiang, Jianquan Li, Xiang Wan, Benyou Wang, Haizhou Li NAACL2024 Links: [arXiv] [Code] Large Language Models (LLMs) provide a possibility to make a great breakthrough in medicine. The establishment of a standardized medical benchmark becomes a fundamental cornerstone to measure progression. However, medical environments in different regions have their local characteristics, e.g., the ubiquity and significance of traditional Chinese medicine within China. Therefore, merely translating English-based medical evaluation may result in contextual incongruities to a local region. To solve the issue, we propose a localized medical benchmark called CMB, a Comprehensive Medical Benchmark in Chinese, designed and rooted entirely within the native Chinese linguistic and cultural framework. While traditional Chinese medicine is integral to this evaluation, it does not constitute its entirety. Using this benchmark, we have evaluated several prominent large-scale LLMs, including ChatGPT, GPT-4, dedicated Chinese LLMs, and LLMs specialized in the medical domain. We hope this benchmark provide first-hand experience in existing LLMs for medicine and also facilitate the widespread adoption and enhancement of medical LLMs within China. Our data and code are publicly available at this https URL. |
|
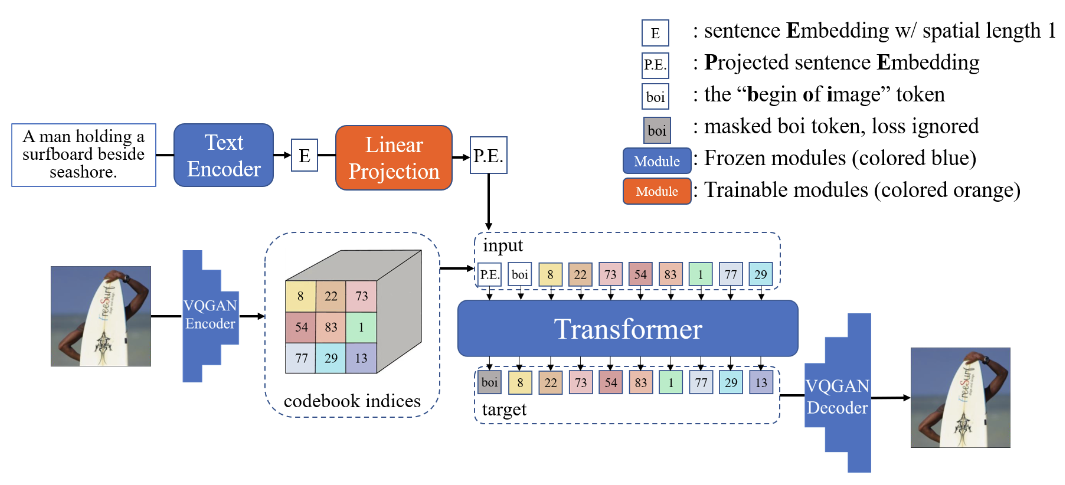
Zhihong Chen*, Guiming Hardy Chen*, Shizhe Diao, Xiang Wan, Benyou Wang ACL2023 Findings Links: [arXiv] [Code] Masked language modeling (MLM) has been one of the most popular pretraining recipes in natural language processing, e.g., BERT, one of the representative models. Recently, contrastive language-image pretraining (CLIP) has also attracted attention, especially its vision models that achieve excellent performance on a broad range of vision tasks. However, few studies are dedicated to studying the text encoders learned by CLIP. In this paper, we analyze the difference between BERT-style and CLIP-style text encoders from three experiments: (i) general text understanding, (ii) vision-centric text understanding, and (iii) text-to-image generation. Experimental analyses show that although CLIP-style text encoders underperform BERT-style ones for general text understanding tasks, they are equipped with a unique ability, i.e., synesthesia, for the cross-modal association, which is more similar to the senses of humans. |

|
Zhihong Chen, Feng Jiang, Junying Chen, Tiannan Wang, Fei Yu, Guiming Hardy Chen, Hongbo Zhang, Juhao Liang, Chen Zhang, Zhiyi Zhang, Jianquan Li, Xiang Wan, Benyou Wang, Haizhou Li arXiv Links: [arXiv] [Code] This paper presents our efforts to democratize ChatGPT across language. We release a large language model "Phoenix", achieving competitive performance among open-source English and Chinese models while excelling in languages with limited resources (covering both Latin and non-Latin languages). We believe this work will be beneficial to make ChatGPT more accessible, especially in countries where people cannot use ChatGPT due to restrictions from OpenAI or local goverments. |
|
|
|
|
|
I practiced Taekwondo from 2008 to 2015 and received 1st Dan Black Belt. I was a badminton college team member during my undergrad. I practiced clarinet for years when I was young but currently I'm more into guitar for its chorus. I am more than interested in piano and music theory but haven't got a chance to learn them formally. I am an introverted person yet open towards different culture and values. I speak multiple languages/dialects, including English, Mandarin, Teochew, Cantonese and a bit of Malay and Indonesian. Hope to explore more in the future : ) |
|
|